
はじめに
ChatGPTやClaudeに何かを質問したとき、AIがあなたのサイトの中身を参照しているかもしれません。
でも、Googleアナリティクス(GA4)では、その実態はほとんど見えません。
「自分のサイトはAI界隈でどれくらい話題になっているのだろう?」
そんな素朴な疑問から、Claude Code(Anthropic公式のAI開発支援ツール)を伴走相手にして、自作の計測の仕組みを作ってみました。結果、2日間で763件のAIアクセスが観測され、なかなか興味深い発見がありました。本記事ではその結果と、同じことをやりたい方への具体的な手順を共有します。
なぜGA4だけでは足りないのか
AIに関連する「アクセス」には、実は2種類あります。
| 種別 | 内容 | GA4で見える? |
|---|---|---|
| (A) AIボットのクロール | GPTBotやClaudeBotが学習・検索目的で巡回 | ❌ JavaScriptが動かないため見えない |
| (B) AI経由の人間リファラル | ChatGPT回答内の引用リンクから人がクリック来訪 | △ 一部のみ(utm_source=chatgpt.com等が付いた場合のみ) |
つまりGA4では、(A)はほぼ完全に見落としており、(B)も取りこぼしが多い状態です。
サーバー生ログを直接解析する以外に、(A)を捕捉する方法はありません。
結論先出し: 何が分かったか
弊社の本サイト「nmbr.jp」と、代表 渋谷の個人サイト「taiichiroushibuya.com」を対象に、2日間計測した結果のサマリーです。
サイト別のAIボット訪問数
| サイト | 総ヒット | 1位 | 2位 | 3位 |
|---|---|---|---|---|
| taiichiroushibuya.com | 467 | OpenAI 310 (66%) | ByteDance 76 (16%) | Anthropic 74 (16%) |
| nmbr.jp | 296 | Anthropic 125 (42%) | ByteDance 95 (32%) | Google 35 (12%) |
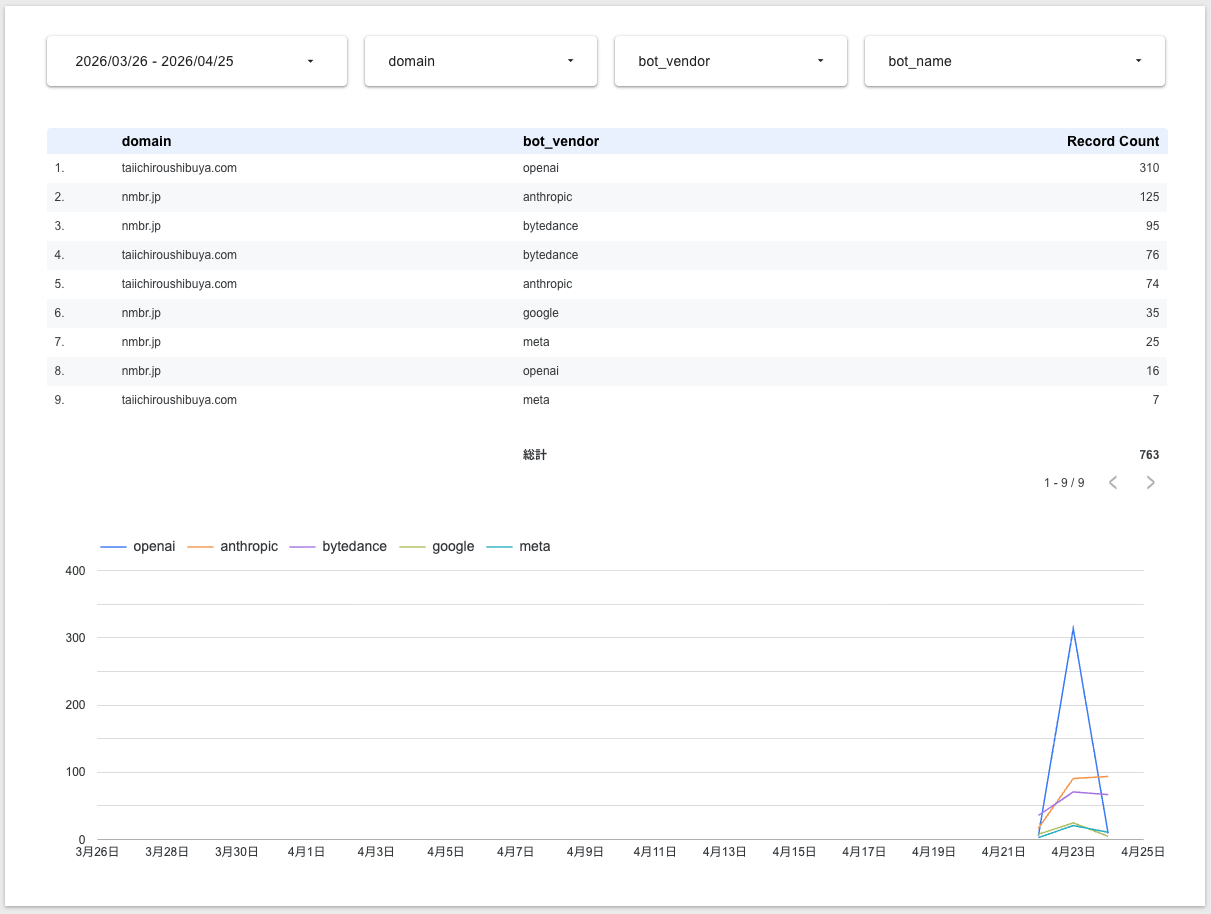
驚いたのは、同じオーナーの2サイトでもAIの興味の偏りが全然違うことです。taiichiroushibuya.com にはOpenAIが集中、nmbr.jp にはAnthropicが優勢。
その他、興味深い発見
- OpenAI: 深夜JST 1時に集中(2日間のOpenAIアクセスの91%がこの時間帯)
- Anthropicは昼間にじわじわ ── 12時〜19時に分散
- 2014年のブログ記事までクロールされていた ── 後述
- ChatGPTから5回、実際の人がサイトに来訪 ── これは後述する
ChatGPT-Userという特殊なボットで判定可能 - 403エラーが59件(taiichiroushibuya.com)── WAFかセキュリティプラグインがボットを弾いている可能性
そもそも「AIボット」って何種類ある?
AIボットは目的別に大きく3種類に分かれます。これを知っておくと結果の読み解きが変わります。
1. 学習用クローラー(training_crawler)
LLM(大規模言語モデル)を訓練するために、大量のWebページを集めて回るボット。
2. AI検索用クローラー(ai_search_crawler)
ChatGPT検索やPerplexityなどの「AI検索」が回答するためのインデックス作成用。学習用とは別動線で動いている。
3. ユーザーアクション由来フェッチャー(user_fetcher)※ 重要
ユーザーがAIに質問した瞬間に、AIがリアルタイムで取得しに来る動きをするボット。
→ つまり 「実際の人があなたのサイトを参照している証拠」 が、これで分かります。
たとえばnmbr.jpには2026-04-24 02:30に、/service と /profile が9秒以内に連続取得されていました。誰かがChatGPTに「nmbr.jpってどんな会社?」と聞いた瞬間と推測できます。
仕組みと構成
全体構成はこうなっています。
WordPress(レンタルサーバー)
↓ アクセスログ生ファイル
↓ rsync over SSH(毎朝8時、自動)
Mac
↓ Pythonでパース・AIボット判定
↓
BigQuery(Googleのデータ倉庫)
↓
データポータル(旧Looker Studio)ポイント:
- 費用: ほぼ0円(BigQueryの無料枠内、月間1TBスキャンまで無料)
- 自動化: macOSの
launchd(タスクスケジューラ)で毎日8時に自動実行 - 手作業: なし(初回セットアップ後は完全自動)
- 開発期間: 1時間(Claude Codeに伴走してもらってこの速度)
AIボット判定パターン(全27種)
これがUser-Agent文字列をどう判定しているかの全パターンです。部分一致(大文字小文字無視)で判定しています。
| ベンダー | UAパターン(部分一致) | カテゴリ | 用途 |
|---|---|---|---|
| OpenAI | gptbot |
training_crawler | ChatGPTの学習データ収集 |
| OpenAI | oai-searchbot |
ai_search_crawler | ChatGPT検索のインデックス |
| OpenAI | chatgpt-user ⭐ |
user_fetcher | ChatGPTユーザーの即時取得 |
| Anthropic | claudebot |
training_crawler | Claudeの学習データ収集 |
| Anthropic | claude-user ⭐ |
user_fetcher | Claudeユーザーの即時取得 |
| Anthropic | claude-searchbot |
ai_search_crawler | Claudeの検索用インデックス |
| Anthropic | anthropic-ai |
training_crawler | (旧UA、互換のため残置) |
| Perplexity | perplexitybot |
ai_search_crawler | Perplexity検索のインデックス |
| Perplexity | perplexity-user ⭐ |
user_fetcher | Perplexityユーザーの即時取得 |
google-extended |
training_crawler | Gemini等の学習データ | |
google-cloudvertexbot |
ai_search_crawler | Vertex AI Agent用 | |
googleother |
training_crawler | Google各種AI研究用 | |
| Meta | meta-externalagent |
training_crawler | Llama学習データ収集 |
| Meta | meta-externalfetcher ⭐ |
user_fetcher | Meta AIユーザーの即時取得 |
| Meta | meta-webindexer |
ai_search_crawler | Meta AI検索のインデックス |
| Meta | facebookbot |
training_crawler | (旧UA、互換のため残置) |
| Apple | applebot-extended |
training_crawler | Apple Intelligence学習用 |
| Mistral | mistralai-user ⭐ |
user_fetcher | Mistralユーザーの即時取得 |
| Amazon | amazonbot |
training_crawler | Amazon Nova / Alexa学習 |
| DuckDuckGo | duckassistbot ⭐ |
user_fetcher | DuckDuckGo AIの即時取得 |
| You.com | youbot |
ai_search_crawler | You.com検索のインデックス |
| Cohere | cohere-training-data-crawler |
training_crawler | Cohereの学習データ |
| Cohere | cohere-ai |
training_crawler | Cohereの学習データ |
| Diffbot | diffbot |
training_crawler | ナレッジグラフ・学習用 |
| xAI | grokbot |
training_crawler | Grokの学習データ |
| ByteDance | bytespider |
training_crawler | Doubao(豆包)等の学習データ |
| Common Crawl | ccbot |
training_crawler | 公開Webアーカイブ(多くのLLMが利用) |
⭐ 印が「実ユーザーが向こう側にいる」可能性が高いボット。
ご参考: 各社の公式ドキュメントで定期的にUAが追加・変更されています。最新情報を反映するには ai.robots.txt というコミュニティリストが便利です。
判定ロジック本体
判定ロジック自体はとてもシンプルで、以下の数行です。
def detect_bot(user_agent: str):
"""User-AgentからAIボットを判定。ヒットしなければNoneを返す。"""
if not user_agent:
return None
ua_lower = user_agent.lower()
for pattern, name, category, vendor in AI_BOT_PATTERNS:
if pattern in ua_lower:
return {"bot_name": name, "bot_category": category, "bot_vendor": vendor}
return None「上記のUAパターンに含まれているか?」を順に確認するだけ。複雑なことは何もしていません。精度を上げる工夫(IPアドレスでの詐称検出など)は後ほど段階的に追加する予定です。
BigQueryに送っているデータ項目
抽出したAIボットアクセスは、BigQueryの2テーブル(ドメイン別)に蓄積しています。スキーマは以下の通りです。
| 項目名 | 型 | 必須 | 説明 |
|---|---|---|---|
timestamp |
TIMESTAMP | ✓ | アクセス時刻(タイムゾーン保持)。日次パーティションキー(クエリのスキャン量削減用) |
remote_ip |
STRING | ✓ | アクセス元IPアドレス。将来のIP逆引き検証で詐称ボット判定に使う |
method |
STRING | HTTPメソッド(GET / POST等) | |
path |
STRING | アクセスされたパス(/blog/2014/03/...等)。どのページが読まれたかを示す主要指標 |
|
status |
INTEGER | HTTPステータスコード(200/404/403等)。403はWAFで弾かれた可能性あり | |
bytes_sent |
INTEGER | レスポンスサイズ(バイト)。重い画像が読まれているか軽量HTMLだけかが分かる | |
referer |
STRING | リファラ。AIボットの場合ほぼ空(-)だが、念のため保持 |
|
user_agent |
STRING | 元のUA文字列をフルで保持。判定根拠の証跡として残す | |
bot_name |
STRING | ✓ | 判定された具体的なボット名(例: GPTBot, ChatGPT-User) |
bot_category |
STRING | ✓ | カテゴリ(training_crawler / ai_search_crawler / user_fetcher) |
bot_vendor |
STRING | ✓ | ベンダー名(openai / anthropic / perplexity 等)。集計の主軸。クラスタリングキー |
log_file |
STRING | ✓ | 取り込み元のログファイル名(例: nmbr.jp.access_log_20260424.gz)。冪等性担保用 |
loaded_at |
TIMESTAMP | ✓ | BQへ取り込んだ時刻。後追いの監査用 |
パフォーマンス設計
- パーティション:
DATE(timestamp)の日次分割 → 「直近7日」を見るとき1週間分しかスキャンしない - クラスタリング:
bot_vendor, bot_name→ 「OpenAIだけ」「ClaudeBotだけ」のフィルタが超高速
これで数年分溜めても、よくある期間集計クエリは1MB程度しかスキャンせず、ほぼ無料で運用できます。
構築で詰まったところ(他の方が真似する時の参考に)
壁1: レンタルサーバー上でPythonが動かない
最初はレンタルサーバー上で完結させるつもりでした。サーバーが直接BigQueryに送れば一番シンプルです。
ところが、契約しているプランのPythonが古すぎて(3.6系)、最新ライブラリが動きません。共有レンタルサーバーなので、必要な開発ツールを追加でインストールすることもできません。
→ Mac側で動かす方針に変更。自宅PCで毎朝8時に自動実行する形にしました。Macの利点はFileVaultで暗号化されている上、launchdという機能でタスクスケジューリングが標準で使える点です。
壁2: 「動いているように見えた」のに実データが0件
自動実行は2日連続で成功していて、ログファイルもダウンロードできていました。なのにBigQueryへの投入は0件。
調査したところ、契約しているレンタルサーバーのアクセスログは標準形式とは少し違っていて、先頭に仮想ホスト名(www.example.com)が付与される独自形式でした。私のパーサーは標準形式しか想定していなかったため、すべての行で照合失敗していました。
標準: 1.2.3.4 - - [日付] "GET /path" 200 ...
独自: www.example.com 1.2.3.4 - - [日付] "GET /path" 200 ...
↑ これが追加されている修正は正規表現に1行足すだけ:
LOG_PATTERN = re.compile(
r'(?:\S+ )?' # ← オプショナルなホスト名(独自形式対応)を追加
r'(?P<ip>\S+) \S+ \S+ '
r'\[(?P<ts>[^\]]+)\] '
r'"(?P<req>(?:[^"\\]|\\.)*)" '
r'(?P<status>\S+) (?P<bytes>\S+) '
r'"(?P<ref>(?:[^"\\]|\\.)*)" "(?P<ua>(?:[^"\\]|\\.)*)"'
)たった1行ですが、これで5,019行のログすべてが100%パース成功するようになりました。「動いているように見える」と「実データが入っている」は違うという良い教訓になりました。
壁3: AIボットの種類が日々増えている
調査開始時に18種類想定していましたが、各社の公式ドキュメントを丁寧に確認したら27種類に増えました。Amazonbot, DuckAssistBot, GrokBotなど、つい最近登場したものも多い。この領域は3か月ごとにメンテが必要そうです。
データから読み取れた興味深いこと
サイトによって「興味を持つAI」が違う
ご紹介した通り、taiichiroushibuya.comはOpenAIに、nmbr.jpはAnthropicに偏っていました。
これはコンテンツの性質、サイト構造、被リンクパターンによって、各社のクローラーが取捨選択している結果と推測されます。各AIベンダーは独自のシード(クロール起点)を持っており、たどり着き方の差で偏りが出るのでしょう。
これが意味するのは、「あなたのサイトのAI訪問者の構成は、あなたのサイトの個性を映している」ということ。SEOで言うところの「Google向けに最適化」と同様、「OpenAI向け / Anthropic向け」という話かもしれませんが、狙ってできるかと言われると、私はまだ解を持っていません。
時間帯のクセ
- OpenAI: 深夜JST 1時に集中(298件中298件、つまり1回のバースト)
- Anthropic: 12時〜19時に分散(リアルタイム性を重視?)
- Bytespider(ByteDance): 0時、4時、22時にピーク(夜行性?)
各社のクロール戦略の違いが鮮明に見えます。サーバー負荷を気にするなら、深夜帯のリソース配分を見直すヒントにもなります。
12年前のブログ記事が、いま「AIに刺さって」いる
弊社のnmbr.jpで、ChatGPT-User(=実ユーザーがChatGPTに質問した瞬間にAIが取得しに来る動き)が踏んだページの中に、2014年3月29日のブログ記事がありました。
タイトルは ──「他社サイトのアクセス数が分かると噂の「SimilarWeb」を検証してみました」。
12年前にWebアクセス解析の話題で書いた記事が、いまAIに参照されている。
サイトアクセス解析の話題が、いまや「AI」に解析されているという、ちょっとした皮肉と感慨があります。
過去のコンテンツが今もAIの中で参照されうる。新規記事だけでなく、過去記事のメンテも改めて意味を持つ時代が来たことを実感します。
これからやりたいこと
数日分のデータを観察して、いくつか追加でやりたいことが見えてきました。
- 数か月分溜めて季節変動・トレンドを見る ── AI利用の伸びが直接見える指標になりうる
- IPアドレスでの「なりすまし検証」 ── User-Agentは詐称可能(
curl -A "GPTBot"で誰でも偽れる)。各社が公開しているIPレンジと突き合わせれば偽物を弾ける - AIに対するクロール許可ポリシーの整理 ── 学習に使われたい? 拒否したい?を明確にする(
robots.txt/llms.txtの整備)
まとめ
- AIに「読まれている」前提でコンテンツを作る時代が来ています
- GA4だけでは見えない世界が、サーバーログを使えば可視化できます
- 自分でやるとちょっとした技術ハードルはありますが、無料枠の範囲で十分実現可能
- 何より、実際に測ってみると意外な発見がたくさんあります
そして今回、ゼロから設計→実装→デプロイまで1時間で組み上げられたのは、ひとえにClaude Codeとの伴走のおかげです。エンジニア専任のチームを持たなくても、こういう「ちょっとした計測基盤」を素早く立ち上げられる時代になりました。
ご質問・ご相談があれば、お気軽にお声がけください。
付録: 技術スタック早見表
| 項目 | 使ったもの |
|---|---|
| サーバー | エックスサーバー(スタンダードプラン) |
| CMS | WordPress |
| ログ取得 | rsync over SSH |
| パース・整形 | Python 3 + 標準ライブラリ |
| データ蓄積 | Google BigQuery(無料枠) |
| 自動実行 | macOS launchd(毎日8時) |
| 可視化 | データポータル(旧Looker Studio、無料) |
| 開発支援 | Claude Code |
費用: BigQueryは月間1TBスキャンまで無料、ストレージは10GBまで無料。AIボットの行数は1日数百〜千件レベルなので、数年分溜めても無料枠内です。
コメント